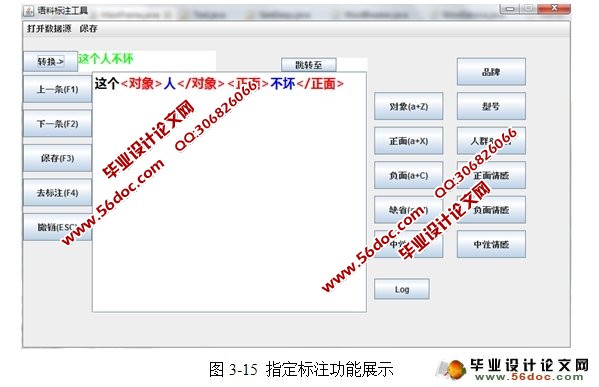
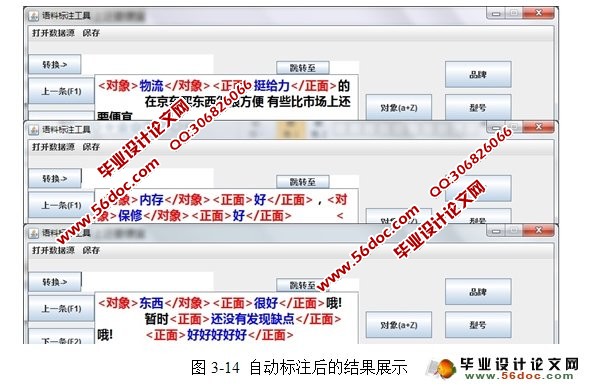
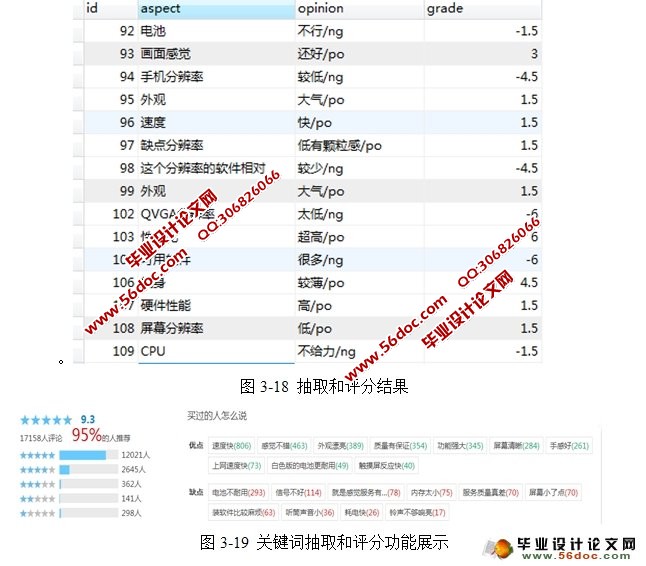
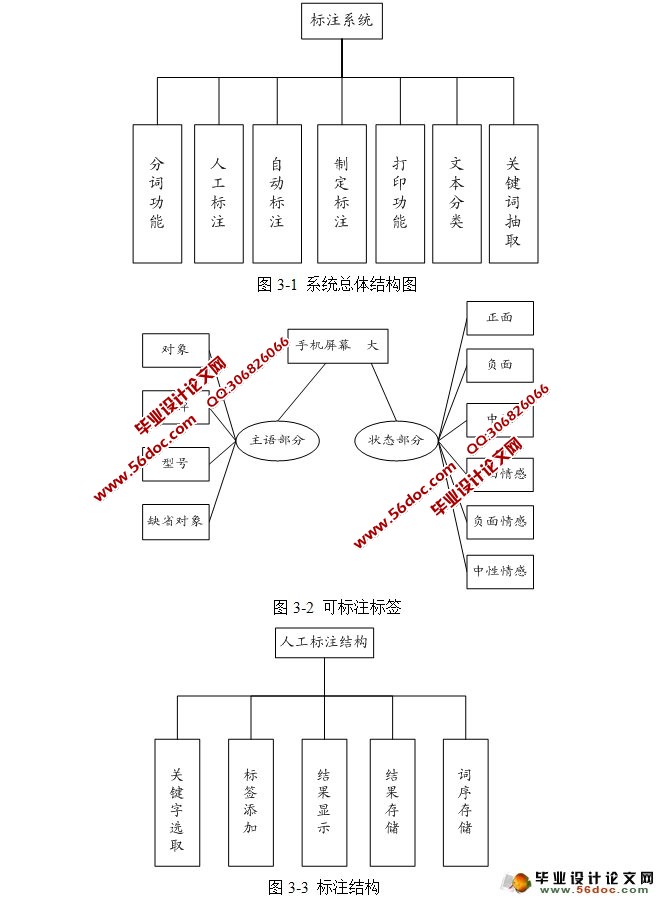
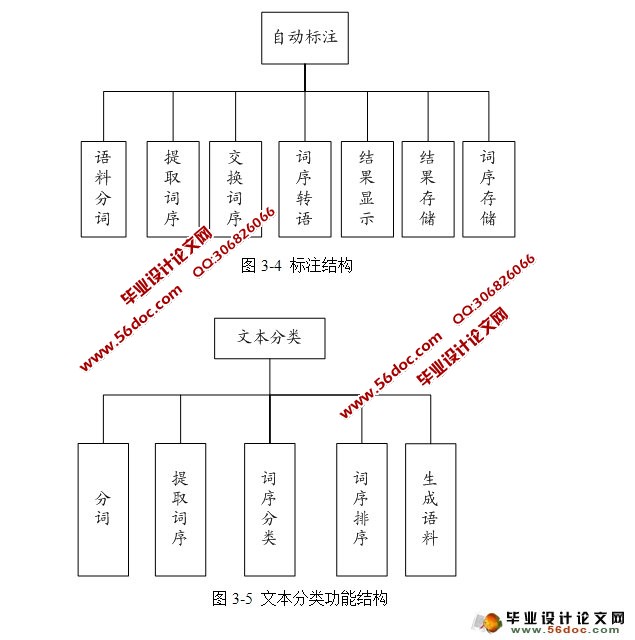
基于分词的语料标注系统的设计与实现(JAVA,Eclipse,MySQL) 来源:wenku163.com 资料编号:WK16312101 资料等级:★★★★★ %E8%B5%84%E6%96%99%E7%BC%96%E5%8F%B7%EF%BC%9AWK16312101 我要下载该资源 资料介绍 基于分词的语料标注系统的设计与实现(JAVA,Eclipse,MySQL)(任务书,开题报告,中期检查表,文献综述,外文翻译,毕业论文22000字,程序代码) 使用计算机处理中文语言中的情感一直是目前自然语言处理的一个研究热点。而最大的问题是缺少词义标注语料库。该文介绍了如何使用自动化的语料标注工具来协助人工构建大规模、高质量的词义标注语料库,并且讨论了构建语料库最基本的几个问题:制定标注规范、选择标注集以及标注过程中的质量监控。 该语料标注工具是要实现对语料的分词、对标注人员的标注结果进行记录、学习并推荐标注结果、文本分类、标注后语料内容的抽取。 基于分词的语料标注工具的设计思想是利用中国科学研究院的分词系统ICTCLAS将语料分词后,采用主动学习以及文本分类的方法,自动选择信息量更为丰富或可能是低频义项的未标注语料提供给标注者进行标注,使用系统记录当前人工标注前后的词性序列,如此反复以达到由半自动到自动标注的转换。 本系统分为以下几个功能。 (1)分词功能 分词功能提供了四种标注方法:计算所一级标注、计算所二级标注、北大一级标注、北大二级标注。 (2)人工标注功能 标注熟语料的输出格式可根据实际需求进行方便更改,本系统采用的是对象与评价的标注格式。 (3)自动标注功能 对语料库中已经存在的语料词序进行自动标注,并提供纠错功能。最大化的减少人工工作量,最小化的减少错误量。 (4)指定语句标注功能 指定文本或语料的分词和自动标注,可用来验证已标注语料的正确率和简单判断语料库规模。 (5)打印功能 用于展示、修改、删除已经存储了的词性序列集合。 (6)文本分类功能 作为标注的预处理工作,用来提高人工标注质量和效率。 (7)关键词抽取功能 从标注后的熟语料中挖掘标注信息,生成对象评价,为后续工作提供材料。 目 录 摘 要 I Abstract II 1 绪论 1 1.1 引言 1 1.2 选课目的及意义 1 1.3 本课题研究的可行性 2 2 开发工具及关键技术概述 3 2.1 开发工具介绍 3 2.2 开发运行环境 4 2.3 MySQL数据库 5 2.3.1 SQL语言 5 2.3.2 MySQL 5 2.4 中国科学研究院分词系统ICTCLAS 7 2.5 文本分类 8 2.5.1 中文文本分类 8 2.5.2 算法 8 3 系统总体设计与实现 10 3.1 系统设计 10 3.1.1 总体框架 10 3.1.2 人工标注详细结构 11 3.1.3 自动标注模块详细结构 13 3.1.4 文本分类模块详细结构 13 3.1.5 系统架构作用及视图 14 3.2 系统各功能模块分析与实现 15 3.2.1 分词功能 15 3.2.2 标注功能 16 3.2.3 数据存储 24 3.2.4 关键词抽取和评分功能 27 3.2.5 文本分类 28 4 数据库分析设计与实现 33 4.1 E-R图 33 4.2 数据库实现 34 4.2.1 数据库表设计 34 4.2.4 索引的设计 35 结 束 语 37 致 谢 38 参考文献 39 附录一 汉语文本词性标注标记集的规范 40 附录二 标注规范 42