摘要
网络中的资源非常丰富,但是如何有效的搜索信息却是一件困难的事情。建立搜索引擎就是解决这个问题的最好方法。本文首先详细介绍了基于英特网的搜索引擎的系统结构,然后从网络机器人、索引引擎、Web服务器三个方面进行详细的说明。为了更加深刻的理解这种技术,本人还亲自实现了一个自己的搜索引擎――新闻搜索引擎。
新闻搜索引擎是从指定的Web页面中按照超连接进行解析、搜索,并把搜索到的每条新闻进行索引后加入数据库。然后通过Web服务器接受客户端请求后从索引数据库中搜索出所匹配的新闻。
本人在介绍搜索引擎的章节中除了详细的阐述技术核心外还结合了新闻搜索引擎的实现代码来说明,图文并茂、易于理解。
Abstract
The resources in the internet are abundant, but it is a difficult job to search some useful information. So a search engine is the best method to solve this problem. This article fist introduces the system structure of search engine based on the internet in detail, then gives a minute explanation form Spider search, engine and web server. In order to understand the technology more deeply, I have programmed a news search engine by myself.
The news search engine is explained and searched according to hyperlink from a appointed web page, then indexs every searched information and adds it to the index database. Then after receiving the customers' requests from the web server, it soon searchs the right news form the index engine,
In the chapter of introducing search engine, it is not only elaborate the core technology, but also combine with the modern code,pictures included, easy to understand.
引言
面对浩瀚的网络资源,搜索引擎为所有网上冲浪的用户提供了一个入口,毫不夸张的说,所有的用户都可以从搜索出发到达自己想去的网上任何一个地方。因此它也成为除了电子邮件以外最多人使用的网上服务。
搜索引擎技术伴随着WWW的发展是引人注目的。搜索引擎大约经历了三代的更新发展:
第一代搜索引擎出现于1994年。这类搜索引擎一般都索引少于1,000,000个网页,极少重新搜集网页并去刷新索引。而且其检索速度非常慢,一般都要等待10秒甚至更长的时间。在实现技术上也基本沿用较为成熟的IR(Information Retrieval)、网络、数据库等技术,相当于利用一些已有技术实现的一个WWW上的应用。在1994年3月到4月,网络爬虫World Web Worm (WWWW)平均每天承受大约1500次查询。
大约在1996年出现的第二代搜索引擎系统大多采用分布式方案(多个微型计算机协同工作)来提高数据规模、响应速度和用户数量,它们一般都保持一个大约50,000,000网页的索引数据库,每天能够响应10,000,000次用户检索请求。1997年11月,当时最先进的几个搜索引擎号称能建立从2,000,000到100,000,000的网页索引。Altavista搜索引擎声称他们每天大概要承受20,000,000次查询。
2000年搜索引擎2000年大会上,按照Google公司总裁Larry Page的演讲,Google正在用3,000台运行LINUX系统的个人电脑在搜集Web上的网页,而且以每天30台的速度向这个微机集群里添加电脑,以保持与网络的发展相同步。每台微机运行多个爬虫程序搜集网页的峰值速度是每秒100个网页,平均速度是每秒48.5个网页,一天可以搜集超过4,000,000网页
搜索引擎一词在国内外因特网领域被广泛使用,然而他的含义却不尽相同。在美国搜索引擎通常指的是基于因特网的搜索引擎,他们通过网络机器人程序收集上千万到几亿个网页,并且每一个词都被搜索引擎索引,也就是我们说的全文检索。著名的因特网搜索引擎包括First Search、Google、HotBot等。在中国,搜索引擎通常指基于网站目录的搜索服务或是特定网站的搜索服务,本人这里研究的是基于因特网的搜索技术。
系统概述
搜索引擎是根据用户的查询请求,按照一定算法从索引数据中查找信息返回给用户。为了保证用户查找信息的精度和新鲜度,搜索引擎需要建立并维护一个庞大的索引数据库。一般的搜索引擎由网络机器人程序、索引与搜索程序、索引数据库等部分组成。
搜索引擎的构成
网络机器人
网络机器人也称为“网络蜘蛛”(Spider),是一个功能很强的WEB扫描程序。它可以在扫描WEB页面的同时检索其内的超链接并加入扫描队列等待以后扫描。因为WEB中广泛使用超链接,所以一个Spider程序理论上可以访问整个WEB页面。
为了保证网络机器人遍历信息的广度和深度需要设定一些重要的链接并制定相关的扫描策略。
索引与搜索
网络机器人将遍历得到的页面存放在临时数据库中,如果通过SQL直接查询信息速度将会难以忍受。为了提高检索效率,需要建立索引,按照倒排文件的格式存放。如果索引不及时跟新的话,用户用搜索引擎也不能检索到。
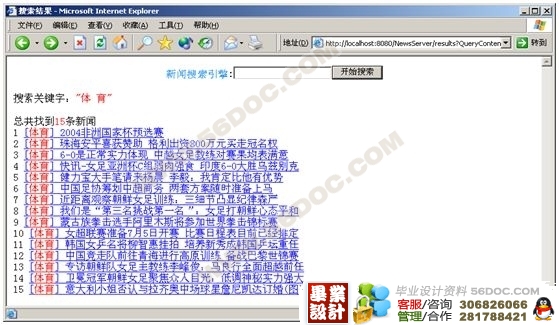
用户输入搜索条件后搜索程序将通过索引数据库进行检索然后把符合查询要求的数据库按照一定的策略进行分级排列并且返回给用户。
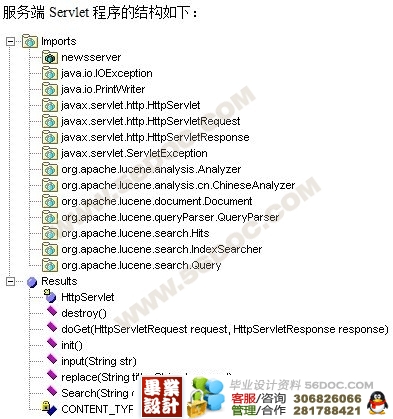
Web服务器
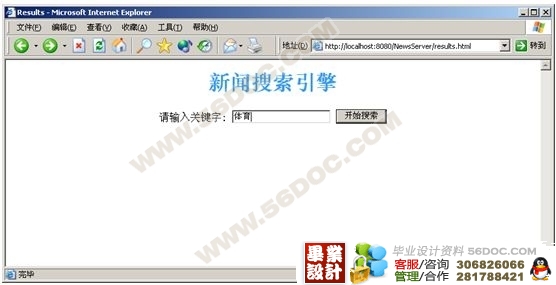
客户一般通过浏览器进行查询,这就需要系统提供Web服务器并且与索引数据库进行连接。客户在浏览器中输入查询条件,Web服务器接收到客户的查询条件后在索引数据库中进行查询、排列然后返回给客户端。
搜索引擎的主要指标及分析
搜索引擎的主要指标有响应时间、召回率、准确率、相关度等。这些指标决定了搜索引擎的技术指标。搜索引擎的技术指标决定了搜索引擎的评价指标。好的搜索引擎应该是具有较快的反应速度和高召回率、准确率的,当然这些都需要搜索引擎技术指标来保障。
召回率:一次搜索结果中符合用户要求的数目与用户查询相关信息的总数之比
准确率:一次搜索结果中符合用户要求的数目与该次搜索结果总数之比
相关度:用户查询与搜索结果之间相似度的一种度量
精确度:对搜索结果的排序分级能力和对垃圾网页的抗干扰能力
小节
以上对基于因特网的搜索引擎结构和性能指标进行了分析,本人在这些研究的基础上利用JAVATM技术和一些Open Source工具实现了一个简单的搜索引擎――新闻搜索引擎。在接下来的几章里将会就本人的设计进行详细的分析。
目录
目录 1
摘要 3
第一章 引言 4
第二章 搜索引擎的结构 5
2.1系统概述 5
2.2搜索引擎的构成 5
2.2.1网络机器人 5
2.2.2索引与搜索 5
2.2.3 Web服务器 6
2.3搜索引擎的主要指标及分析 6
2.4小节 6
第三章 网络机器人 7
3.1什么是网络机器人 7
3.2网络机器人的结构分析 7
3.2.1如何解析HTML 7
3.2.2 Spider程序结构 8
3.2.3如何构造Spider程序 9
3.2.4如何提高程序性能 11
3.2.5网络机器人的代码分析 12
3.3小节 14
第四章 基于LUCENE的索引与搜索 15
4.1什么是LUCENE全文检索 15
4.2 LUCENE的原理分析 15
4.2.1全文检索的实现机制 15
4.2.2 Lucene的索引效率 15
4.2.3 中文切分词机制 17
4.3 LUCENE与SPIDER的结合 18
4.4小节 21
第五章 基于TOMCAT的WEB服务器 22
5.1什么是基于TOMCAT的WEB服务器 22
5.2用户接口设计 22
5.3.1客户端设计 22
5.3.2服务端设计 23
5.3在TOMCAT上部署项目 25
5.4小节 25
第六章 搜索引擎策略 26
6.1简介 26
6.2面向主题的搜索策略 26
6.2.1导向词 26
6.2.3权威网页和中心网页 27
6.3小节 27
参考文献 28
|
