聚类分析技术在图书馆中的应用(包含选题审批表,任务书,开题报告,中期检查报告,毕业论文13400字)
摘 要:大家去图书馆中时,会看到不同的书籍会按照书的种类或者性质来分类,比如:社科类,文学类,计算机类等等。这就是将图书进行了分类,而在图书馆的计算机搜索功能中也正是运用了聚类分析技术来将所有的书籍按照不同的种类或使用情况来进行分类,分成不同的簇,便于学生进行搜索查询。聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。它是一种重要的人类行为。聚类分析的目标就是在相似的基础上收集数据来分类。这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。在现代社会中,聚类分析技术在各个领域得到了广泛的应用,而其中最重要的表现之一就是在图书馆中的应用。聚类分析技术在图书馆中搜索引擎的应用可以使学生在图书馆杂乱无章的图书信息中快速准确的找到自己想要找到的图书信息,聚类分析还可以自动生成便于用户查询的网页聚类系统。聚类分析还可用于对用户查询的结果进行处理,以一种超链接的层次方式提交给用户,大大提高查询的查全率和查准率。
关键词:聚类分析;计算机;簇,数据;搜索;图书馆。
Application of Association Rules Mining in Digital Library
Abstract:As is known to all, we went to the library in time, will see different books according to the book of the type or nature of classification, such as: Social Sciences, literature, computer and so on. Cluster analysis of physical or abstract objects grouped into by similar objects consisting of multiple types of analysis process. It is one of the most important human behavior. Cluster analysis of the target is in the similar collection based on data classification. These methods were used as a description of the data, a measure of the similarity between different data sources, as well as the data source classification into different clusters. In modern society, the clustering analysis technology in various fields has been widely used, and one of the most important is one of the performance of the application in the library. This is sorted the books in the library, and the computer search function also is the use of cluster analysis technology to put all the books in the different kind or nature to be classified, divided into different clusters, which is convenient for students to undertake a search query. Clustering analysis technology in the application of the search engine in the library can make the students be the library books information quickly and accurately find themselves want to find a information, clustering analysis can also automatically generate for the user query webpage clustering system. Cluster analysis can also be used to the user query results are processed in a hyperlink, the level is presented to a user query, greatly improve the recall ratio and precision ratio.
Key words:computer;cluster;cluster analysis;data;search;library。
主要内容和要求
聚类分析是把一组对象划分成一系列有意义的子集的过程,最大的组内相似性为同一聚类中的对象尽可能地相似,最小的组间相似性为不同聚类中的对象尽可能地不同。在这一过程中没有任何关于类分的先验知识,没有教师指导,仅靠事物间的相似性作为类属划分的准则,是一种无监督机器学习方法。
图书馆在学校教学、科研和学科建设中的地位越来越重要,如何从海量的图书流通数据中发现有价值的信息,对于加强图书馆资源建设和改善管理工作是非常关键的。
图书馆管理系统中引入数据挖掘技术,利用聚类分析中的K-means算法对图书馆馆藏图书借阅使用情况进行了聚类挖掘,并将挖掘结果进行分析,从而制定出相应的决策,有针对地丰富馆藏资源和优化图书馆的馆藏布局。
在图书馆管理系统中,书目的馆藏信息、文献的流通情况、读者基本信息有着详细的记录。通过挖掘文献使用规律,对图书馆节约次数进行聚类分析,可得哪些图书借阅频率高,哪些图书的借阅频率比较低。从而制定出相应的决策,有针对性的丰富馆藏资源和优化图书馆的馆藏布局。
主要功能
通过对馆藏图书进行聚类挖掘,文章从读者对馆藏图书的借阅次数角度来衡量馆藏图书的利用情况,捕捉图书馆在馆藏溅射方面的某些特征。对聚类结果产生的第一类图书,忧郁他们的借阅需求比较大,可以考虑调整此类图书流通的册数,及时购买副本,及时对图书的完好性进行检查,保证在读者进行借阅的时候都能借到该类图书。另外一方面,根据聚类结果,在馆藏布局方面,可以考虑将借阅需求比较大的此类图书排列在图书馆醒目的位置,方便读者借阅,同时对借阅需要比较少的图书进行分析,找到借阅次数少的原因,对此次图书的数量和位置做相应的调整。
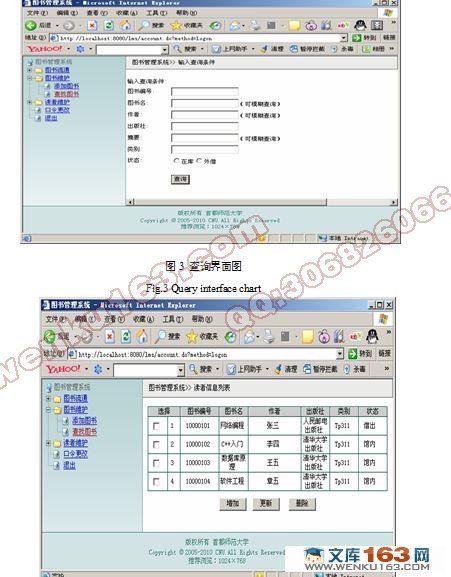
目 录
摘 要 1
关键词 1
1 前言 2
1.1 问题的提出与研究意义 2
1.2 聚类分析在图书馆中的应用现状 3
1.3 问题剖析 4
1.3.1 主要问题 4
1.3.2 主要功能 4
2 可行性研究 4
3 市场调查与需求分析 6
3.1 市场调查 6
3.2 需求分析 6
3.3 可靠性和可用性分析 6
3.3.1 可靠性分析 6
3.3.2 可用性分析 6
3.4 出错处理需求 7
3.5 将来可能提出的要求 7
4 聚类分析的理论基础和技术支持 7
4.1 聚类分析技术的由来 7
4.2 聚类分析技术的概念 7
4.3 聚类分析算法技术支持 8
5 概要设计 9
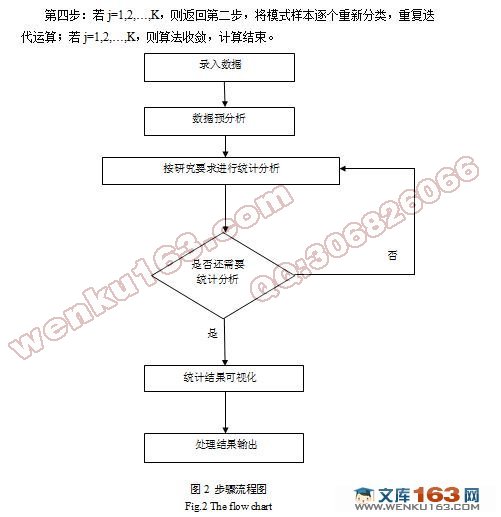
5.1 统计方法 9
5.2 聚类分析程序 10
5.3 聚类分析中常用的聚类算法 11
5.3.1 CLARANS算法 11
5.2.2 CURE算法 12
5.3.3 BIRCH算法 12
5.3.4 DBSCAN算法 13
5.3.5 STING算法 14
5.3.6 COBWEB算法 14
5.3.7 模糊聚类算法FCM 15
5.4 聚类算法的性能比较 15
6 详细设计和实现过程 16
7 系统测试 19
8 心得体会 20
9 结束语 20
10 参考文献 20
致谢 21
|
